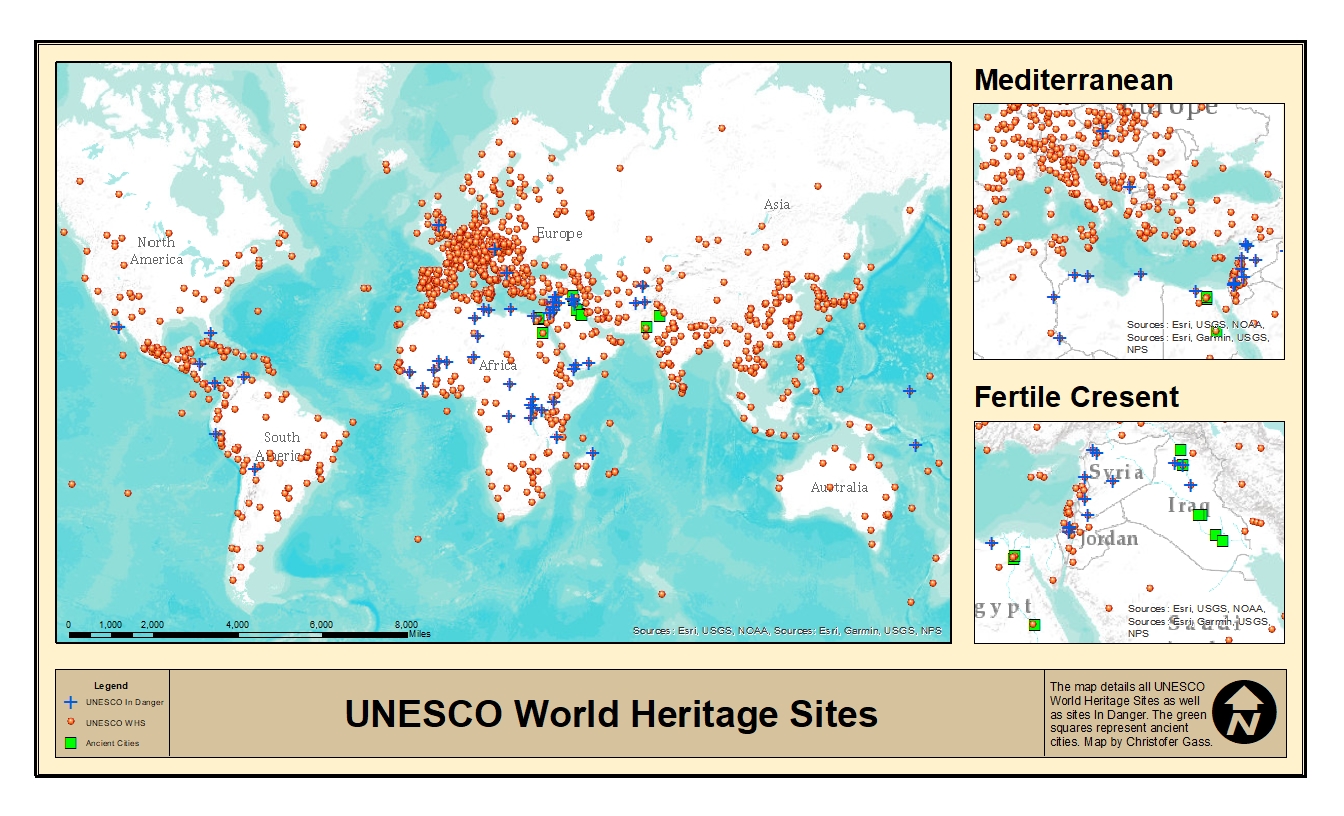
The team has focused the last week on data collection and creating content, while reviewing our project plan and deliverables. In regards to our data, the Caldecotts are (for the most part) completed, data is being cleaned, and our existing visualizations are getting an upgrade. In our meeting, Emily and I reported on the Caldecott data and how essential the YouTube read alongs were when examining protagonists. While speaking with Meg and Kelly, we realized that we did not include gender for the animals and nonhuman protagonists (where available) and are going to work on filling that in before the 12th. For example, in Olvia by Ian Falconer, Olivia is a female pig. We originally labelled Olivia as just an animal, but we will now include gender. Authors will often assign gender to their animal and nonhuman protagonists, and it should be included in our analysis. During our meeting, Meg brought up an excellent point about how we are reporting gender in our data, and we had a tough but important discussion regarding our practices as well as our audience. I recommend everyone read Meg’s blog post for more information on the topic and our discussion: https://whowins.commons.gc.cuny.edu/2020/04/26/our-data-in-and-beyond-the-gender-binary/
While Kelly was waiting for the Caldecotts, she worked on the Newbery visualizations in Tableau. She changed the view to Story, making it easier for our audience to navigate through the visualizations. Kelly was also put in contact with a woman who has experience with Tableau. She shared tips and best practices, which Kelly will use with the Newbery and Caldecott data.
With Kelly working on the visualizations, Meg, Emily, and I will work on completing blog posts for the website. Topics include the U.S. Census, how our research methods have changed due to covid-19, and other Book Awards that many parents and educators are unaware of. We will also continue to create content for Twitter, and participate in Day of DH 2020. We are focusing on Twitter to build interest for our project and share our methods, and will use our Instagram account to share our visualizations and graphics. Before the presentation on the 12th, we will review the website for any broken links and missing pages, and will do a final run through once we embed the visualizations on our site. We want to make sure that our visualizations will display properly and that our audience can successfully interact with them.
We are looking forward to the dress rehearsal next week and then launching our project at the GC Digital Showcase. I know that this has been a challenging semester for all of us, but I am proud of both my team and the Heritage Reconstruction team for what we have accomplished.