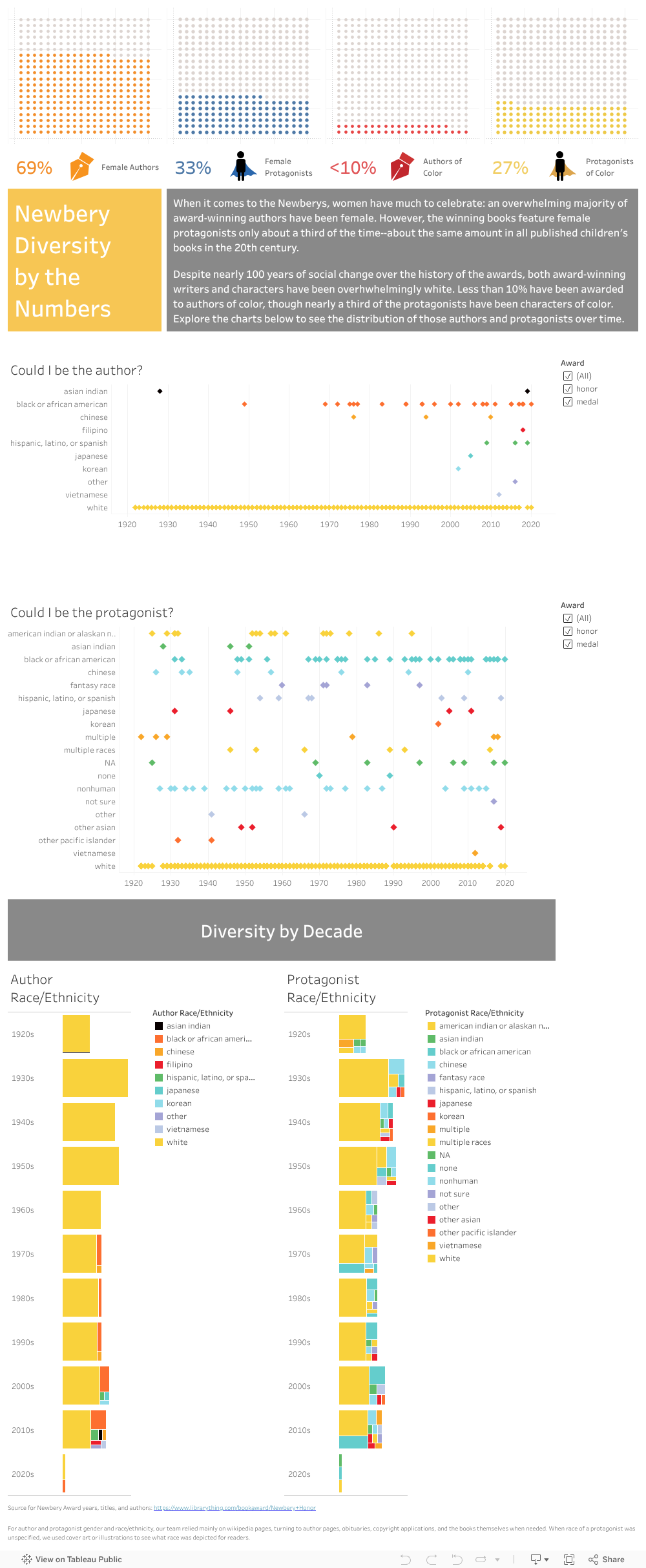
This week was all about loosening what had become a tight focus on getting required tasks done. It started with the in-class critique of our project presentation which nudged me to return to the more expansive “What if?” thinking with which we launched the project. Micki suggested really playing with the visualizations in counterfactual ways. What if we don’t represent whiteness in the graphics?* What if we push back against the census categories?
My initial play with the first question was deflating: in both protagonist and author graphs, an early award winner of color makes the removal of the “nearly solid bar” of data representing whiteness not considerably more interesting than with it. So, I’ll need to play around this week with conditional statements that sort awardees by decade or that translate our race/ethnicity data into more equitable categories than the Census divisions.
Also widening my scope was my videoconference with GC Digital Fellow Rafael Portela to review the python code I’d created to scrape Caldecott awardees. While the Newbery scrape yielded data just as I’d hoped, the two Caldecott scrapes resulted in messier .csv files that required loads of cleaning. I’d turned to Rafael (Rafa) in hopes of figuring out whether that mess was a result of the architecture of the sites’ HTML or my code.
Our meeting underscored what DH is all about: a manner of thinking more than an amalgamation of skills. Having asked me to send him the python files in advance, Rafa began by saying, “I haven’t done any data scraping with python myself.” But, he had already played with the files I’d sent, and he had looked at my code less as a data scraper than as a text parser. He asked just the right questions to get me thinking about ways my code might have been more efficient and effective.
He did indeed confirm that the sites’ HTML was what caused my Caldecott scrapes to be messy. But, he also helped me identify two ways that I might have counteracted that. First, he noted that using the element inspector in Chrome reveals a little more about the architecture of the site than merely viewing the source code. (It turns out that there was a hidden attribute in the anchor tags of the Madison Public Library site that would have helped me grab both medal winners and honorees in one go, though I still would have had a lot of cleaning to do.)
He also pointed out that using python not just for scraping but also for cleaning would have been wise. Using regular expressions to parse the data may have resulted in clean columns of year of award, title, author, and illustrator (if different from the author). He also pointed me to Beautiful Soup’s documentation to consider ways to handle multiple attributes of scraped tags in the future.
If our group has time or if we continue the project beyond the scope of the semester, I’m hoping to try using regular expressions to parse scraped data in code rather than relying on Excel’s text-to-columns feature and a lot of post-scraping work. Meanwhile, I’ll continue to do research to fix our current data set (this week, I got rid of ? and null values in the protagonist data), and I’ll start to push our visualizations further as Georgette and Emily finish up the Caldecott research.
*Actually, Georgette had suggested this in last Sunday’s team meeting, so it was a double nudge from Micki.